
20 Aug Scaling WebRTC to 10,000 Devices: Taming Signaling Storms, $100k TURN Bills & SFU Meltdowns
Why 200-device success doesn’t translate to 10k streams – and how to architect for exponential WebRTC growth without budget overruns or performance fires.
Your 200-device WebRTC pilot passed testing. Then came the mandate: Scaling WebRTC and Deploy 10,000 cameras by Q4. Suddenly, signaling traffic explodes 100x, TURN relay costs hit $95k/month, and SFU nodes buckle at 13 streams/core. This isn’t linear growth; it’s a physics problem where architecture choices make or break production.
Most teams discover too late that when scaling WebRTC, it behaves fundamentally differently. Throughput isn’t the bottleneck—it’s the nested dependencies between signaling coordination, relay economics, and computational limits that trigger cascading failures.
In this technical blog, we dissect empirical data from 10k+ stream deployments. We also reveal how to:
- Slash TURN costs 40% while surviving UDP-blocked networks
- Prevent signaling pods from crash-looping at 5k connections
- Autoscale SFUs before CPU queues trigger quality collapse
- Build observability that correlates subsystem failures
If you’re migrating from POC to production scaling WebRTC, here’s what actually breaks—and how to out-engineer it.
A successful 200-device WebRTC proof of concept (PoC) faces fundamental architectural limitations when you want to scale to 10,000 devices. Scaling WebRTC systems exhibits non-linear characteristics, with three critical failure vectors emerging at scale:
1. Signaling State Explosion (N² Complexity)
Problem:
Peer negotiation (SDP offers/answers, ICE candidates) becomes a coordination bottleneck. Stateful signaling servers storing session data in memory fail catastrophically under load:
- Memory Pressure: 10k devices exchanging 350-byte SDP messages daily (20k keep-alive renegotiations + 10k camera toggles + 3k network changes) = 11.6GB+ volatile state
- Concurrency Collisions: Race conditions during concurrent SDP updates cause “no remote description” errors
- Brittleness: Pod restarts purge session state, terminating active calls
Failure Symptoms:
- Random connection drops during scaling webRTC events
- ICE negotiation timeouts
- Database write latency spikes (>100ms)
Solution: Stateless Signaling Architecture
- Decouple signaling state using Redis Cluster:

- WebSocket servers maintain only transient connections
- Redis persists SDP/ICE data with TTL expiration
- Eliminates session affinity requirements and pod-specific state
While stateless signaling solves coordination bottlenecks, it merely sets the stage for media delivery. The real cost monster emerges when devices hit network barriers. Corporate firewalls and hotel Wi-Fi often block UDP – WebRTC’s preferred transport. When 20% of your 10,000 devices fall back to TURN relays, bandwidth requirements don’t just increase: they detonate. This isn’t incremental growth; it’s a step function where architecture choices directly translate to five or six-figure cloud bills.
2. TURN Relay Cost Escalation
Problem:
~20% of enterprise networks force TCP fallback via TURN servers, creating bandwidth/cost inflection:
- Bandwidth Demand:
1.2 Mbps/stream × 10,000 streams × 86,400s/day = 1,036.8 TB/month - Cost Calculation:
1,036.8 TB × 1,024 GB/TB × $0.09/GB (AWS egress) = $95,406/month - Performance Impact:
- 25-40ms latency penalty per relay hop
- TCP/TLS handshake overhead
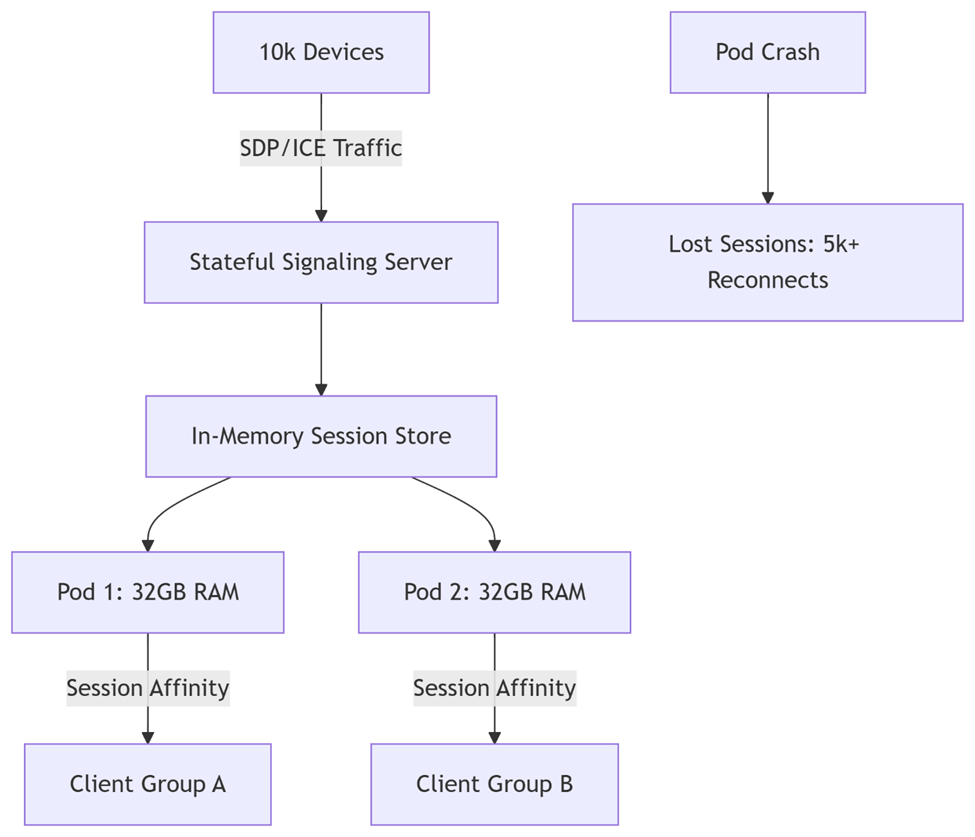
Figure 1: Stateful signaling creates fragile session maps. Pod failures trigger mass renegotiations
Operational Constraints:
- Single 10Gbps NIC supports ≤900 HD relays (theoretical max)
- Concurrent authentication storms during shift changes
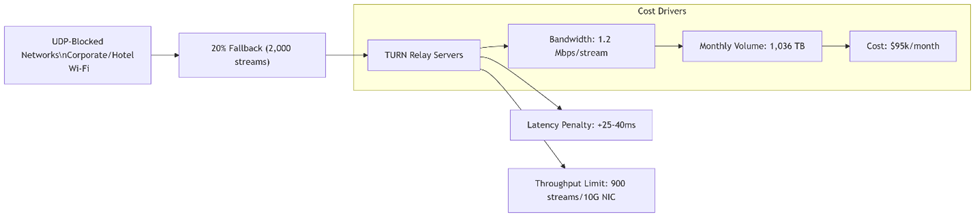
Figure 3: Network restrictions force 20% of streams into TURN relay paths, creating exponential cost growth. Each relayed stream consumes bandwidth while adding latency.
Mitigation Strategies:
- Credential Staggering: Issue TURN credentials with 5-minute validity offsets
- TCP/443 Relaying: Bypass UDP blocks without HTTPS tunneling:
coturn -n –tls-listening-port=443 –no-udp - Stream Pruning: Suspend relay after 60 seconds of no RTP packets
- Edge POPs: Deploy relays in >5 AWS regions (target <500km user↔POP distance)
Optimized TURN deployment controls costs but shifts pressure upstream. The relayed streams now converge at Selective Forwarding Units (SFUs), which face a computational paradox: The same features that save bandwidth – simulcast layers and dynamic bitrate switching – consume disproportionate CPU resources. Unlike stateless signaling or bandwidth-heavy TURN, SFUs scale on processor cycles. A single HD stream with three simulcast layers can monopolize 0.8 vCPUs, turning video routing into a physics problem where heat dissipation and core allocation become hard limits.
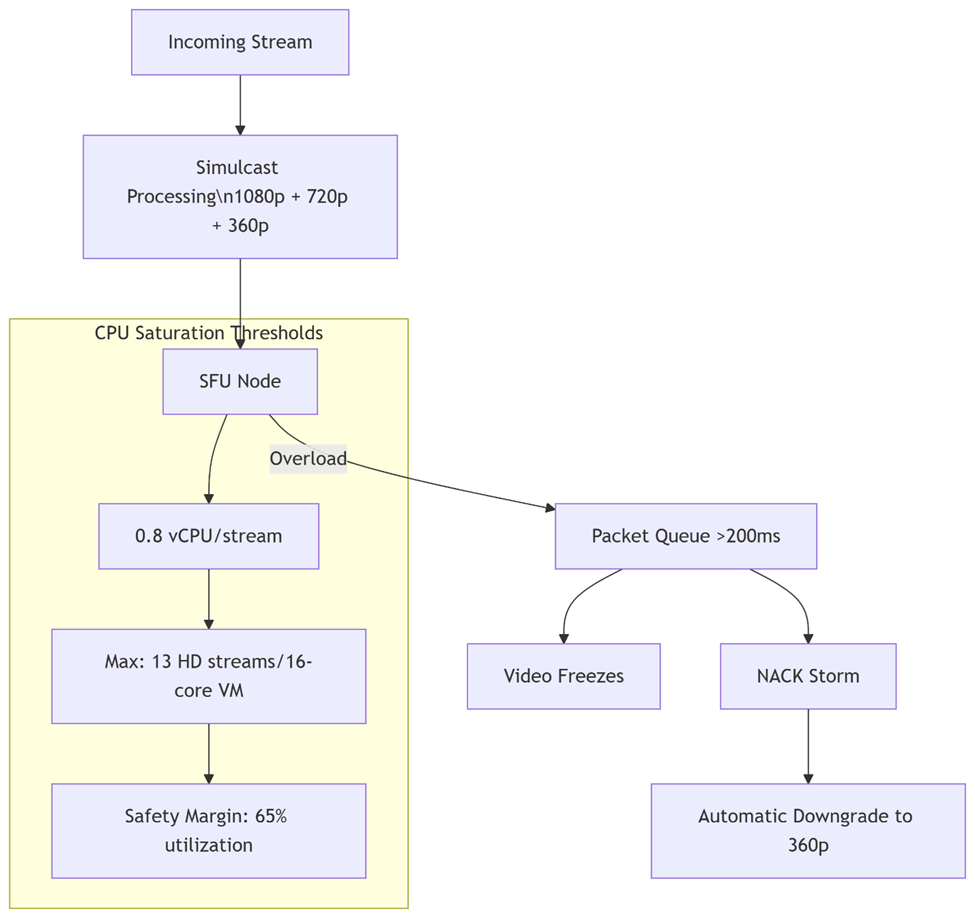
Figure 2: Simulcast processing creates CPU-bound bottlenecks where exceeding 65% utilization triggers quality degradation cascades.
3. SFU Computational Saturation
Problem:
Selective Forwarding Units (SFUs) become CPU-bound due to:
- Simulcast Processing: Decoding 3 video layers (1080p/720p/360p) consumes ~0.8 vCPU per stream
- Dynamic Layer Switching: Congestion-triggered resolution changes cause CPU thrashing
- Sharding Limitations: Regional “hot rooms” with 50+ participants overload single SFU nodes
Capacity Limits:
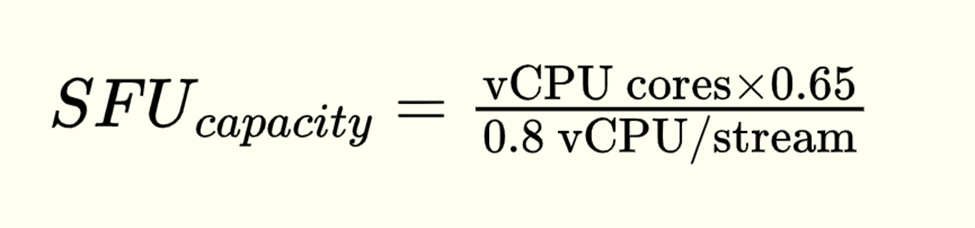
Example: 16-core VM handles ≤13 streams at safe margin
Failure Modes:
- Video freezes (RTP buffer overflows)
- Quality oscillations (bandwidth misestimation)
- Container OOM kills during packet storms
Autoscaling Triggers:
| Metric | Threshold | Action |
| CPU utilization | >70% for 30s | Add pod to cluster |
| Packet queue delay | >200ms | Migrate room to new pod |
| NACK ratio | >8% | Force 360p layer downgrade |
These three subsystems – signaling, TURN, and SFU – form a dependency chain where failures cascade. A signaling collapse drops TURN connections. An overloaded SFU triggers ICE restarts that bombard signaling servers. What appears as ‘video freezing’ could originate from any layer. This interdependency demands holistic observability: Your monitoring must correlate Redis latency spikes with TURN authentication surges and SFU queue depths. Without this, you’re debugging blindfolded while the system burns.
Critical Scaling Dependencies
| Subsystem | Scaling Factor | Primary Constraint | Secondary Impact |
| Signaling | O(N²) connections | Memory/IOPS | Session persistence |
| TURN | Bandwidth (O(N)) | Network throughput | Latency/cost |
| SFU | CPU (O(N)) | Core utilization | Video degradation |
The scaling WebRTC challenge isn’t about any single component failing – it’s about their nonlinear interactions. Signaling scales quadratically (O(N²)), TURN costs scale linearly but with high constants (O(N)), while SFUs hit physical CPU ceilings. This trifecta means that a 50x device increase can create 100x signaling load, 60x bandwidth costs, and 75x CPU demand simultaneously. Vertical scaling fails here; only distributed, stateless systems with regional sharding survive.
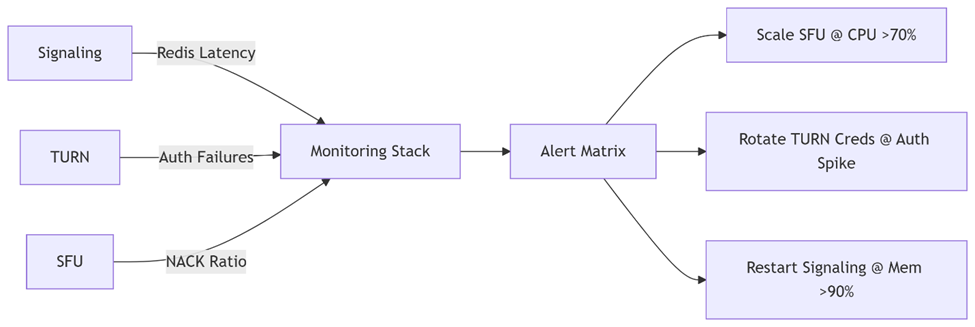
Figure 4: Correlated monitoring prevents cascading failures across subsystems.
Conclusion:
Scaling WebRTC to 10,000 streams isn’t about adding servers—it’s about defeating three nonlinear scaling curves simultaneously:
- Signaling’s O(N²) complexity demands stateless Redis coordination to survive SDP storms
- TURN’s bandwidth economics requires edge POPs and TCP/443 fallbacks to avoid $100k bills
- SFU’s physical CPU limits force sharding + 65% utilization guardrails
The critical insight? These subsystems fail together. A TURN credential storm overloads signaling. SFU saturation triggers ICE restarts that bombard Redis. Victory requires:
- Stateless everything (no sticky sessions, no in-memory state)
- Cost-aware relay routing (idle pruning, regional egress)
- Predictive SFU scaling (queue depth > CPU metrics)
- Correlated observability (trace TURN↔SFU↔signaling events)
The result: A 50x device increase shouldn’t mean 100x complexity. With the architectural patterns above, your system won’t just survive 10k streams—it’ll handle the next 10x leap without refactoring. Now, the real work begins: implementing the playbook.